首先声明:我水平尚浅,如果你正经学RL,去看书或者大佬的博客,比如
我写这个学习记录还有一大原因,目前许多国内各种教程,总是上来甩给观众各种数学概念,然后学生懵懵地把概念啃完,跟着实操做几步,背几步,能把考试题啊面试题啊什么的都做对,就自认为学会了。但是,我认为这不是一个正常的学习过程。我眼中的正常学习过程,是遇到一个个问题,然后不断寻找问题的解决方案,各个知识点的出现有一定的逻辑过程/发展过程。
人工智能有两大基础部分,神经网络和机器学习,前者是一个实在的结构,后者是前者获取智能的方法。机器学习主要分为三种:监督学习、无监督学习和强化学习。
监督学习有点像刷题:我们出一些互相没有显著关联的题目,智能体给出答案,我们将这个答案和正确答案比对,以此训练智能体。
无监督学习有点像寻宝:智能体在大量数据中挖掘潜在结构与内在规律,无监督学习的典型的问题是聚类问题。
强化学习有点像游戏:每次智能体给出操作,我们考虑这个操作的后果与期望的目标,以此训练智能体。
这可能值得强调,强化学习是一种学习方法,强化学习这个概念与使用什么智能体或什么神经网络是相独立的。
下面我们主要讨论的是强化学习:
这里有一个经典的强化学习在干什么的概念图:智能体根据环境做出动作,环境给予智能体反馈,奖罚智能体,并告诉智能体当前世界的状态。
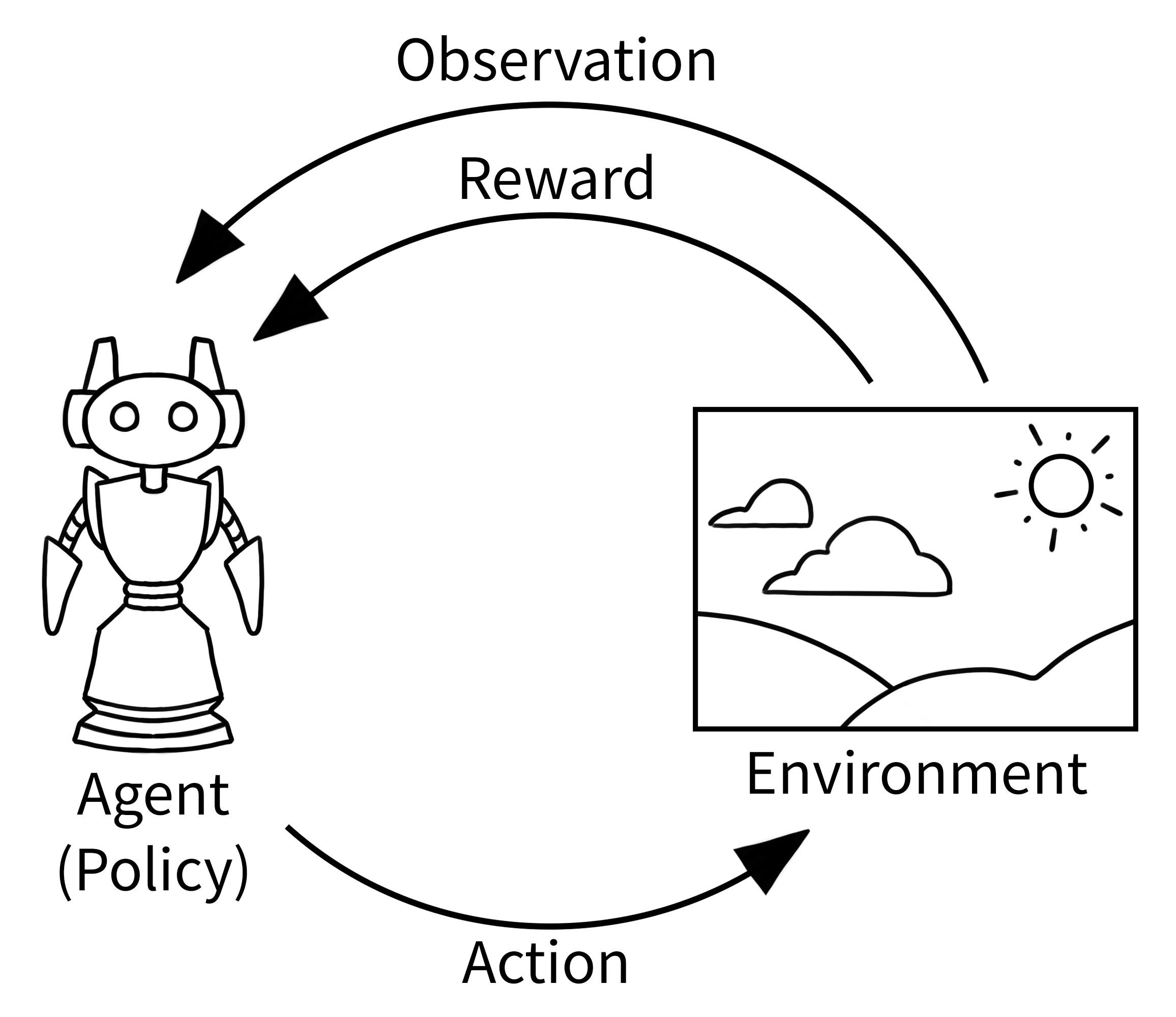
一言以蔽之,强化学习是这样一个模型:智能体从环境获得 Observation,做出 Action 改变环境,针对智能体做的怎么样,我们给出 Reward 进行评判,智能体要做的,是让 Reward 最大。
准备工作
作为准备工作,python 的 gymnasium 是一个实践强化学习的非常好的库,下面所有内容都基于这个库:
首先,创建 python 环境,这里使用 python3.12 是因为这是一个稳定的版本,有torch也有tenserflow,方便之后搞事情……。注意这里装的是 gymnasium 因为 gym 已经停止维护了,安装 gymnasium 时可以带上 [all] 装上所有特性,后续使用各种环境的时候不用单独安装了,适合我这种空间足够的小白玩。去掉 [all] 也是可以的,后续可以根据报错安装对应的环境(QwQ。
conda create --name rl python=3.12 # 创建虚拟环境
conda activate rl # 切换环境
pip install "gymnasium[all]" # 安装 gymnasium,国内环境可以加一个加速镜像源 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple安装完成后,新建一个 .py 文件,写上这段例程,然后 python ./文件名.py 运行它:
# 对于这个案例,你可以使用 `pip install "gymnasium[classic-control]"` 安装 gym 需要的特性(像我一样 all 了之后可以忽略这行)
import gymnasium as gym
# 创建我们的训练环境 —— 一个小车顶着一个杆子,要平衡杆子不让它倒下
env = gym.make("CartPole-v1", render_mode="human")
# 重置环境到起始状态,每次 env.step 前都一定要 reset 哦
observation, info = env.reset()
# observation 是智能体从环境中能获得的信息,比如小车位置、小车速度、杆子角度、……
# info 提供了一些额外 debug 信息,在我们入门的旅程中,不需要在意它
print(f"Starting observation: {observation}")
# 一个可能的输出: [ 0.01234567 -0.00987654 0.02345678 0.01456789]
# 对应: [小车位置, 小车速度, 杆子角度, 杆子旋转角速度]
episode_over = False
total_reward = 0
while not episode_over:
# 从所有可能的动作中选一个: 0 = 小车向左, 1 = 小车向右
action = env.action_space.sample() # 目前先随机一个动作吧
# 采取这个动作,看看会发生什么
observation, reward, terminated, truncated, info = env.step(action)
# 在这个案例中:杆子每保持直立一步,reward 就增加 1
# 当杆子落得太远,terminated 会置为真 (智能体失败了)
# 当到达时间限制的时候 truncated 会置 (默认 500 步)
total_reward += reward
episode_over = terminated or truncated
print(f"Episode finished! Total reward: {total_reward}")
env.close()运行后,会出现一个窗口,小车顶着杆子走,很快杆子会落下了,然后结束。
hint:将上面代码中的
action = env.action_space.sample()改成action = int(observation[0]*0.1 + observation[1] + observation[2] + observation[3] > 0)可以获得一个更加智能的智能体。
在这个例子里,我们看到了 gymnasium 的主要特性:使用 gym.make 创建虚拟环境(以 env 为例),使用 env.reset() 重置环境,使用 env.step(action) 执行 Agent 的动作。
在这个例子中,我们实现了平衡着杆子的小车,但要谈到强化学习,我们的旅程才刚刚开始。
Q-Learning
从一个 OIer 的视角,来看看一个问题
为了方便讨论,我们假设智能体从环境得到的 Observation 是离散的,能采取的 Action 也是离散的。在这一节中,我们先以 is_slippery = false 的
import gymnasium as gym
env = gym.make(
'FrozenLake-v1',
desc=None,
map_name="4x4",
is_slippery=False,
reward_schedule=(10,-10,-1),
render_mode="human"
)智能体从环境获得 Observation,做出 Action 改变环境,针对智能体做的怎么样,我们给出 Reward 进行评判,智能体要做的,是让 Reward 最大。
对于环境的每一个状态(暂时假定这能在 Observation 中完全体现出来)与给定的 Action,智能体能得到一个针对性的 Reward,这一关系我们可以用一个表格来表示。表格的每一行表示不同的 Observation,每一列表示不同的 Action,表格中的数值表示 Reward。
这是 Reward 关于 Observation(行)与 Action(列)关系的表格
















诶,那还不简单,我们每次做使得我们马上获得的 Reward 最大的 Action 不就行了……了吗?不对啊不对,在智能体工作过程中,每一步 action 马上得到的 reward 几乎都为 0,在学习过程中也可能遇到为了 reward 总和更高暂时拿负 reward 的情况。
但是,我们可以定义,在某一个 Observation 下采取某个 Action,经过若干步后我们“期望”我们的智能体获得的总 Reward,我们称之为 Q。对于目前这个离散非随机案例,Q 可以是进行这一 Action 后能获得的最大 Reward。熟悉 OI 的小伙伴们马上就能发现,这件事情是可以动态规划求解的。
实际 Q-learning 的公式中,会在 \max\limits_{a'\in\mathbb A}Q(s',a')前面加上一个折扣因子的在 0 到 1 之间系数。这个系数越接近 0,智能体越重视及时回报,越接近 1,智能体越重视长期回报,在最终得分上表现更好,最终公式如下:
总之,我们重复进行这个若干遍来更新 Q,直到达到最大执行步骤数或 Q 表格稳定即可。
动态规划求解 Q 的过程
求得 Q 表格之后,诶,我们就可以每次做使得我们马上获得的 Q 最大/并列最大的 Action 就行了。然而,更多实际强化学习问题中,Observation 与 Action 可能是连续的,智能体每进行一次 Action 后对环境的改变是有一定随机性的。
上面的解决方法很完美,只不过这是 OI 这还不是强化学习。在人工智能问题中,我们想得到一个能解决问题的智能体,它应该是一个有参数的东西,通过调参能解决一大类问题。而不是对于每个不同的环境/Q,都给出一个新的智能体。
说句题外话,我非常希望得到的,是一个可以通过调参(学习),解决人类所有能够解决的问题的智能体。其结构应当不止是一个固定的神经网络模型,其学习所使用的参数不应该是一个固定的参数……
马尔可夫决策模型
为了能够进一步讨论,我们先明确一下刚才说的这个可以调参的智能体是什么,这是一个函数,一个变量是 观测(和过去观测),返回值是采取各种动作的可能性的函数。(下面先不考虑过去观测的作用)我们把这个函数叫做策略函数(policy),记作\pi(s),这个 s代表观测。
这个函数得到采取各种动作的可能性,为了方便表示,我们记\pi(a|s)为在观测s下采取动作 a 的概率。我们所“学习”的东西,是这个函数的参数,我们通过“强化学习“调整参数,目标是得到一个能解决问题的函数。“学习”是学一个函数,这件事对于监督学习也是一样的。而神经网络算法等,是这个函数的实现方式。
当观测空间与动作空间都是有限的且较小的时候,我们可以使用表格法来表达这个函数。
ε-贪婪策略
ε-贪婪策略咋说呢,就是分为探索和利用,最开始探索多,到后面利用多。探索就是随机选一个动作执行,利用就是在 Q 值大的动作里选一个做。边做动作边更新 Q 矩阵。
这里基于上面的例子给一个使用 ε-贪婪策略更新 Q 矩阵的智能体的例子:
from collections import defaultdict
import gymnasium as gym
import numpy as np
class FrozenLakeAgent:
def __init__(
self,
env: gym.Env,
learning_rate: float = 0.1,
initial_epsilon: float = 1,
epsilon_decay: float = 0.999,
final_epsilon: float = 0.1,
discount_factor: float = 1,
):
"""初始化一个 Q-Learning 智能体
参数:
env: gym 环境
learning_rate: 学习率
initial_epsilon: 初始探索率
epsilon_decay: 探索率衰减
final_epsilon: 最终探索率
discount_factor: 折扣因子
"""
self.env = env
# Q 值表,使用 defaultdict 初始化为 0 以便自动初始化未见过的状态
self.qValues = defaultdict(lambda: np.zeros(env.action_space.n))
self.lr = learning_rate # 学习率
self.discount_factor = discount_factor # 折扣因子
# 探索率相关参数
self.epsilon = initial_epsilon
self.epsilon_decay = epsilon_decay
self.final_epsilon = final_epsilon
# 跟踪训练过程
self.training_error = []
def get_action(self, obsv: int) -> int:
"""基于 ε-贪婪策略选择动作
参数:
obsv: 当前观察到的状态
返回:
选择的动作
"""
if np.random.rand() < self.epsilon:
return self.env.action_space.sample() # 探索Explore:随机选择动作
else:
return np.argmax(self.qValues[obsv]) # 利用Exploit:选择 Q 值最高的动作
def update(
self,
obsv: int,
action: int,
reward: float,
terminated: bool,
next_obsv: int
):
"""使用 Q-Learning 更新 Q 值
参数:
obsv: 当前观察到的状态
action: 采取的动作
reward: 获得的奖励
terminated: 是否终止
next_obsv: 下一个观察到的状态
"""
current_q = self.qValues[obsv][action]
max_future_q = np.max(self.qValues[next_obsv]) if not terminated else 0
# Q-Learning 更新公式
new_q = (1 - self.lr) * current_q + self.lr * (reward + self.discount_factor * max_future_q)
self.qValues[obsv][action] = new_q
# 记录训练误差
self.training_error.append(abs(new_q - current_q))
def decay_epsilon(self):
"""衰减探索率 ε"""
self.epsilon = max(self.final_epsilon, self.epsilon * self.epsilon_decay) if self.epsilon > self.final_epsilon else self.epsilon怎么训练这个智能体呢?这样:
n_episodes = 10000
env = gym.make(
'FrozenLake-v1',
desc=None,
is_slippery=False,
success_rate=0.9,
reward_schedule=(10,-10,-1),
map_name="4x4"
)
env = gym.wrappers.RecordEpisodeStatistics(env, buffer_length=n_episodes)
observation, info = env.reset()
tot_reward = 0
agent = FrozenLakeAgent(env)
from tqdm import tqdm
for episode in tqdm(range(n_episodes)):
observation, info = env.reset()
done = False
while not done:
action = agent.get_action(observation)
next_observation, reward, terminated, truncated, info = env.step(action)
agent.update(observation, action, reward, terminated, next_observation)
done = terminated or truncated
observation = next_observation
agent.decay_epsilon()这里获得的 agent.qValues 就是训练的成果了。然后可以将学习参数 ε 设置为 0,对这个模型进行测试:
total_rewards = []
old_epsilon = agent.epsilon
agent.epsilon = 0.0 # 禁用探索以测试学习到的策略
for _ in range(100):
obs, info = env.reset()
episode_reward = 0
done = False
while not done:
action = agent.get_action(obs)
obs, reward, terminated, truncated, info = env.step(action)
episode_reward += reward
done = terminated or truncated
total_rewards.append(episode_reward)
win_rate = np.mean(np.array(total_rewards) > 0)
print(f"Win rate over 100 test episodes: {win_rate * 100}%")
print(f"Average reward over 100 test episodes: {np.mean(total_rewards)}")
print(f"Standard deviation of reward over 100 test episodes: {np.std(total_rewards)}")
# 下面是展示训练得到的 qValues
print(f"Trained Q-values:")
for state, actions in agent.qValues.items():
print(f"State {state}: {actions}")